
Sitemap
A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Pages
Posts
Future Blog Post
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Blog Post number 4
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 3
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 2
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 1
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
portfolio
Portfolio item number 1
Short description of portfolio item number 1
Portfolio item number 2
Short description of portfolio item number 2
publications
Paper Title Number 1
Published in Journal 1, 2009
This paper is about the number 1. The number 2 is left for future work.
Recommended citation: Your Name, You. (2009). "Paper Title Number 1." Journal 1. 1(1). http://academicpages.github.io/files/paper1.pdf
Paper Title Number 2
Published in Journal 1, 2010
This paper is about the number 2. The number 3 is left for future work.
Recommended citation: Your Name, You. (2010). "Paper Title Number 2." Journal 1. 1(2). http://academicpages.github.io/files/paper2.pdf
Paper Title Number 3
Published in Journal 1, 2015
This paper is about the number 3. The number 4 is left for future work.
Recommended citation: Your Name, You. (2015). "Paper Title Number 3." Journal 1. 1(3). http://academicpages.github.io/files/paper3.pdf
talks
Is GPT a Computational Model of Emotion?
Published:
This paper investigates the emotional reasoning abilities of the GPT family of large language models. We advocate a component perspective on evaluation that decomposes models into different aspects of emotional reasoning (appraisal derivation, affect/intensity derivation, and consequent derivation). We report two studies. A correlational study examines how the model reasons about autobiographical memories. An experimental study systematically varies aspects of situations in ways previously shown to impact emotion intensity and coping tendencies. Results demonstrate, even without prompt engineering, GPT predictions closely match human-provided appraisals and emotion labels, though GPT struggled to predict emotion intensity and coping responses. GPT-4 performed best on the first study but performed poorly on the second (though it yielded the best results following minor prompt engineering). The evaluation raises questions about how to utilize the strengths and mitigate the weaknesses of such models, including dealing with variability in responses. More fundamentally, these studies highlight the benefits of the componential perspective on model evaluation.

GPT-4 Emulates Average-Human Emotional Cognition from a Third-Person Perspective
Published:
This work extends recent investigations on the emotional reasoning abilities of Large Language Models (LLMs). Current research on LLMs has not directly evaluated the distinction between how LLMs predict the self-attribution of emotions and the perception of others’ emotions. We first look at carefully crafted emotion-evoking stimuli, originally designed to find patterns of brain neural activity representing fine-grained inferred emotional attributions of others. We show that GPT-4 is especially accurate in reasoning about such stimuli. This suggests LLMs agree with humans’ attributions of others’ emotions in stereotypical scenarios remarkably more than self-attributions of emotions in idiosyncratic situations. To further explore this, our second study utilizes a dataset containing annotations from both the author and a third-person perspective. We find that GPT-4’s interpretations align more closely with human judgments about the emotions of others than with self-assessments. Notably, conventional computational models of emotion primarily rely on self-reported ground truth as the gold standard. However, an average observer’s standpoint, which LLMs appear to have adopted, might be more relevant for many downstream applications, at least in the absence of individual information and adequate safety considerations.

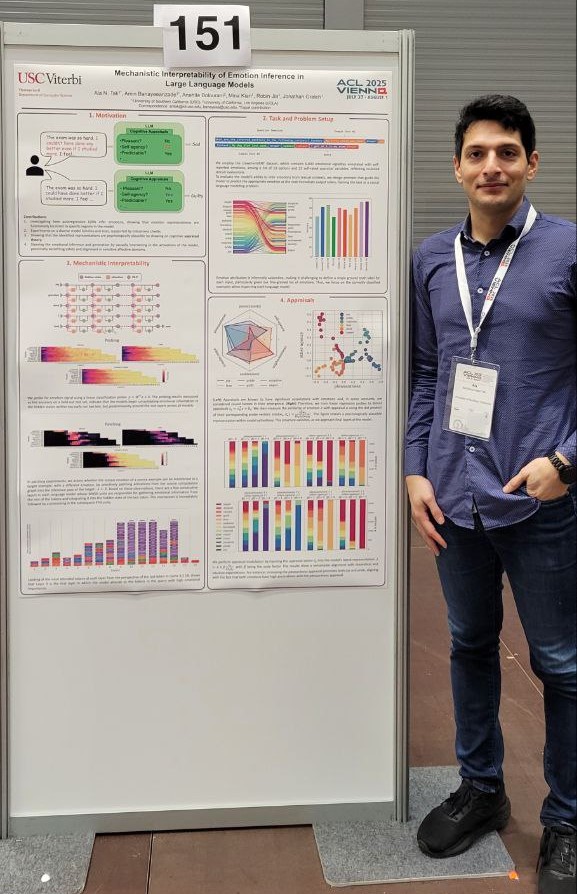
Mechanistic Interpretability of Emotion Inference in Large Language Models
Published:
This work investigates how autoregressive LLMs infer emotions, showing that emotion representations are functionally localized to specific regions in the model. Our evaluation includes diverse model families and sizes and is supported by robustness checks. We then show that the identified representations are psychologically plausible by drawing on cognitive appraisal theory, a well-established psychological framework positing that emotions emerge from evaluations (appraisals) of environmental stimuli. By causally intervening on construed appraisal concepts, we steer the generation and show that the outputs align with theoretical and intuitive expectations. This work highlights a novel way to causally intervene and precisely shape emotional text generation, potentially benefiting safety and alignment in sensitive affective domains.
The 3rd Workshop on Social Influence in Conversations (SICon)
Published:
We are excited to host the Third Workshop on Social Influence in Conversations (SICon 2025) in Vienna, Austria — SICon is a one-day hybrid event, co-located with ACL. As SI dialogue tasks (negotiation, persuasion, therapy, and argumentation) have recently gained traction, this workshop offers a venue to foster discussion on social influence within NLP while involving researchers from other disciplines — e.g., affective computing and the social sciences.

Impact of LLM Alignment on Impression Formation in Social Interactions
Published:
We investigate whether LLMs exhibit patterns of impression formation that align with Affect Control Theory predictions. We compare several preference-tuned derivatives of LLaMA-3 model family (including LLaMA-Instruct, Tulu-3, and DeepSeek-R1-Distill) with GPT-4 as a baseline, examining the extent to which alignment or preference tuning influences the models’ tendencies in forming gender impressions. We find that LLMs form impressions quite differently than ACT. Notably, LLMs are insensitive to situational context: the impression of an interaction is overwhelmingly driven by the identity of the actor, regardless of the actor’s actions or the recipient of those actions.
teaching
Teaching experience 1
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Teaching experience 2
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.